参考这篇文章学习关于APK的知识
Android逆向基础----APK文件结构
APK文件结构:
apk文件实际是一个zip压缩包,可以通过解压缩工具解开。
| META-INF目录 |
存放的是签名信息,用来保证apk包的完整性和系统的安全。 |
| res目录 |
res是resource的缩写,这个目录存放资源文件 |
| AndroidManifest.xml |
是Android应用程序的配置文件,是一个用来描述Android应用“整体资讯”的设定文件, Android系统可以根据这个“自我介绍”完整地了解APK应用程序的资讯,每个Android应用程序都必须包含一个AndroidManifest.xml文件,且它的名字是固定的,不能修改。 |
| classes.dex |
传统的Java程序,首先先把Java文件编译成class文件,字节码都保存在了class文件中,Java虚拟机可以通过解释执行这些class文件。 |
| resources.arsc |
用来记录资源文件和资源ID之间的映射关系,用来根据资源ID寻找资源。 |
APK反编译工具
APK改之理(ApkIDE)v3.5.0 少月增强版
题目给了一张 真的很杂.jpg
使用 binwalk -e 真的很杂.jpg ,解析文件得到一份文件包,得到了下面这些文件:
1
2
3
4
5
6
|
# resources.arsc
# classes.dex
# AndroidManifest.xml
# res目录
# META-INF目录
# 1438.zip
|
这里的 1438.zip 文件可以解压缩打开,和当前目录的文件是一样的。由apk文件实际是一个zip压缩包,可以通过解压缩工具解开。我们可以知道 1438.zip 应该为apk文件,改后缀为 .apk 用 APK IDE打开进行反编译。
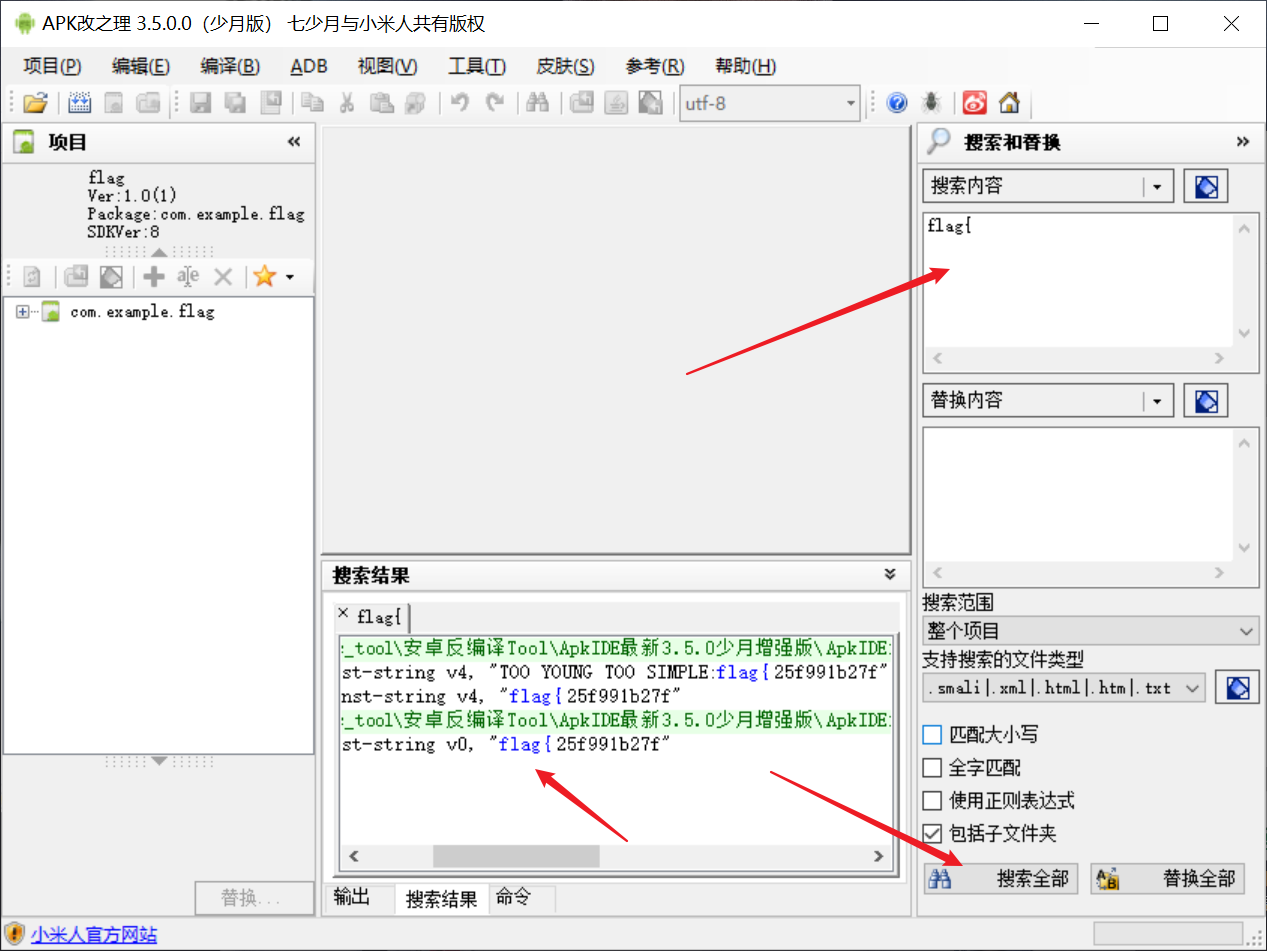
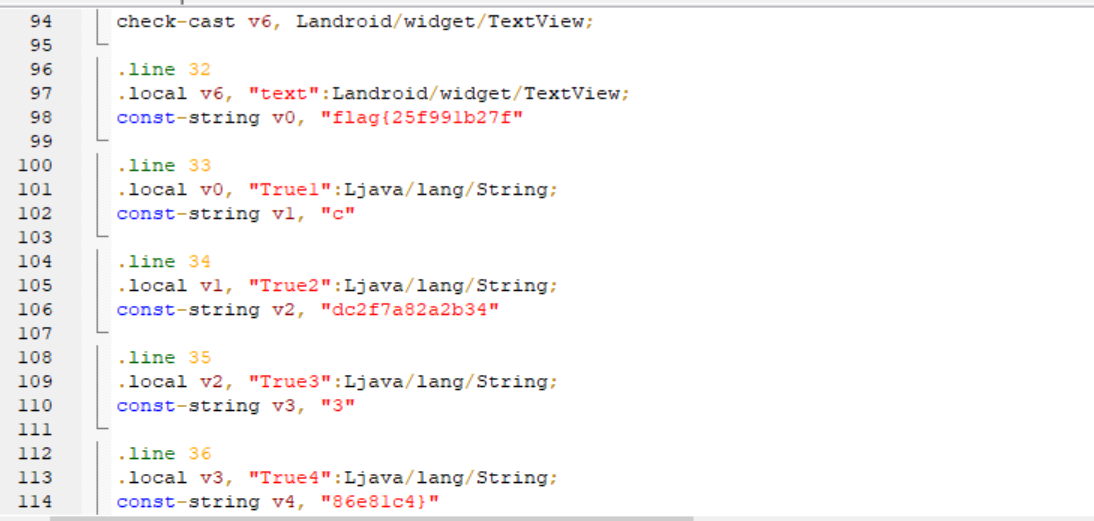
找到 flag{25f991b27fcdc2f7a82a2b34386e81c4}
二维码有三个定位点,通常出题人会让二维码定位点缺失或者反色。
定位点:左上,左下,右上
直接用截屏软件截取定位点,然后补全空缺的,用微信扫二维码拿到 base32 编码,解码得到 flag:

QCTF{Pretty_Sister_Who_Buys_Me_Lobster}
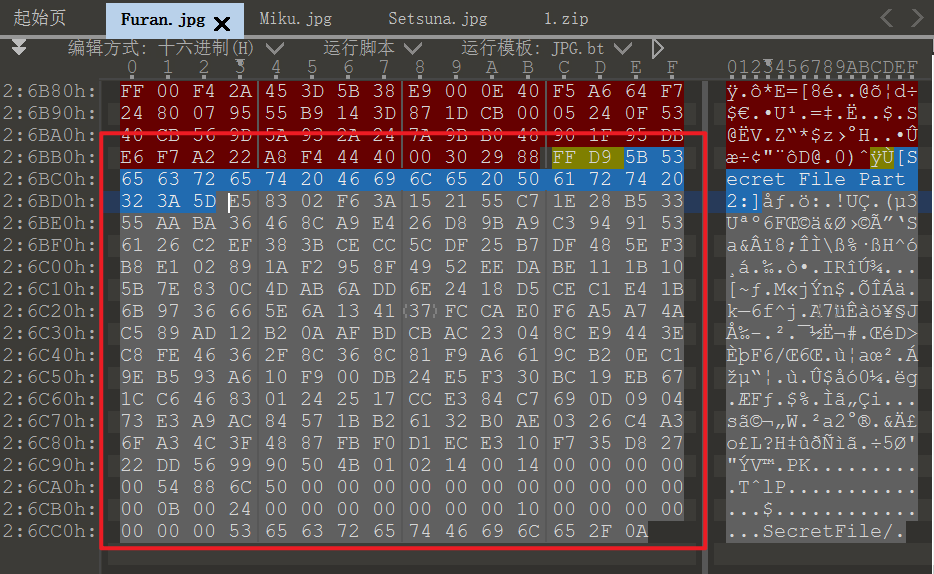
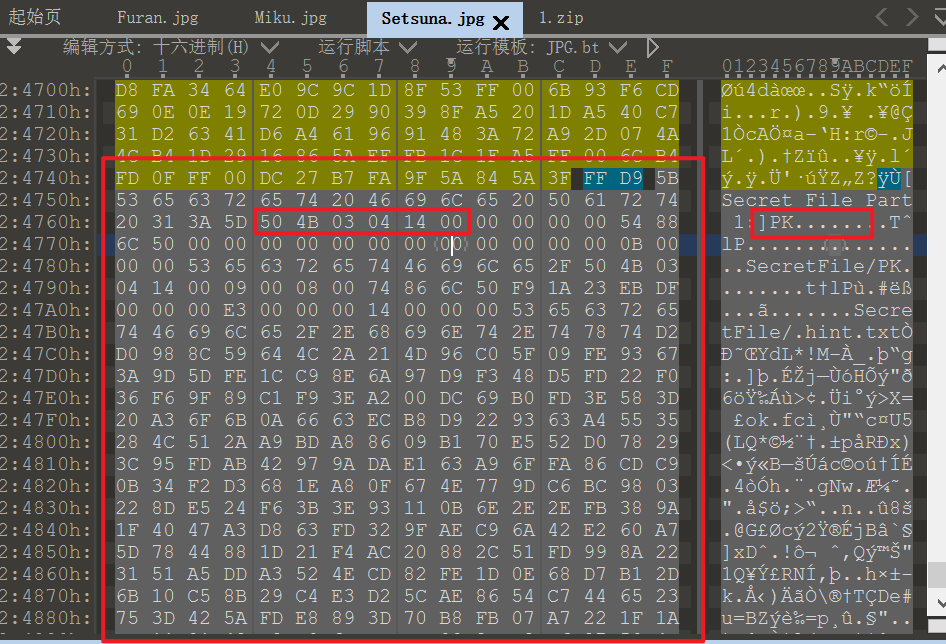
将三张图片用010editor打开,发现每张 jpg 的后面都有隐藏的 ZIP 信息:
1
2
|
Furan.jpg
[Secret File Part 2:]
|
1
2
|
Setsuna.jpg
[Secret File Part 1:]
|
1
2
|
Furan.jpg
[Secret File Part 2:]
|
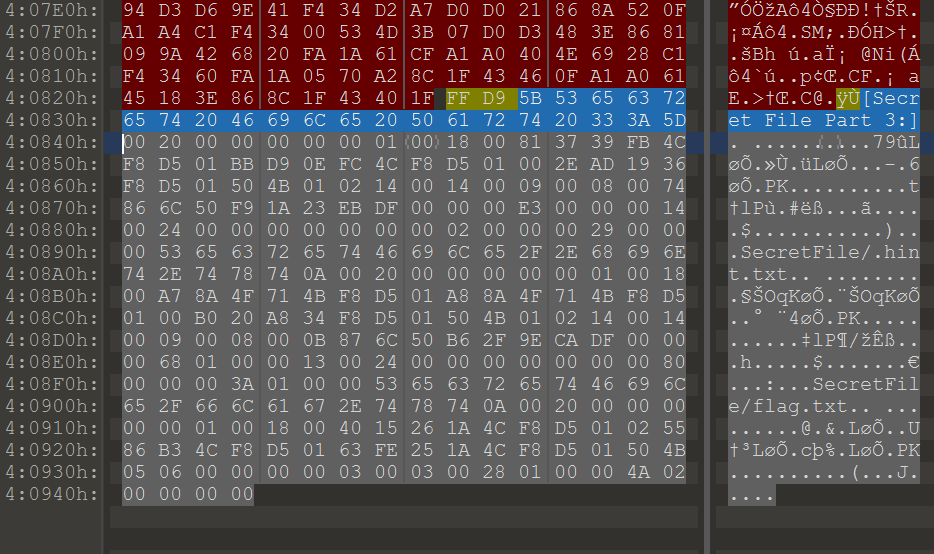
将三张图的 zip 信息提取出来,按顺序排好,保存为 zip文件。
打开后发现是加密的 ,用 Ziperello 爆破密码,弱密码:1234
1
2
3
4
|
# .hint.txt
我用各种baseXX编码把flag套娃加密了,你应该也有看出来。
但我只用了一些常用的base编码哦,毕竟我的智力水平你也知道...像什么base36base58听都没听过
提示:0x10,0x20,0x30,0x55
|
1
2
|
# flag.txt
G&eOhGcq(ZG(t2*H8M3dG&wXiGcq(ZG&wXyG(j~tG&eOdGcq+aG(t5oG(j~qG&eIeGcq+aG)6Q<G(j~rG&eOdH9<5qG&eLvG(j~sG&nRdH9<8rG%++qG%__eG&eIeGc+|cG(t5oG(j~sG&eOlH9<8rH8C_qH9<8oG&eOhGc+_bG&eLvH9<8sG&eLgGcz?cG&3|sH8M3cG&eOtG%_?aG(t5oG(j~tG&wXxGcq+aH8V6sH9<8rG&eOhH9<5qG(<E-H8M3eG&wXiGcq(ZG)6Q<G(j~tG&eOtG%+<aG&wagG%__cG&eIeGcq+aG&M9uH8V6cG&eOlH9<8rG(<HrG(j~qG&eLcH9<8sG&wUwGek2)
|
根据提示,解码应该是 base85,base16,base32,base48,但感觉base48应该出题人写错了。最后用代码解的时候,发现应该是base64解码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import base64
s85 = 'G&eOhGcq(ZG(t2*H8M3dG&wXiGcq(ZG&wXyG(j~tG&eOdGcq+aG(t5oG(j~qG&eIeGcq+aG)6Q<G(j~rG&eOdH9<5qG&eLvG(j~sG&nRdH9<8rG%++qG%__eG&eIeGc+|cG(t5oG(j~sG&eOlH9<8rH8C_qH9<8oG&eOhGc+_bG&eLvH9<8sG&eLgGcz?cG&3|sH8M3cG&eOtG%_?aG(t5oG(j~tG&wXxGcq+aH8V6sH9<8rG&eOhH9<5qG(<E-H8M3eG&wXiGcq(ZG)6Q<G(j~tG&eOtG%+<aG&wagG%__cG&eIeGcq+aG&M9uH8V6cG&eOlH9<8rG(<HrG(j~qG&eLcH9<8sG&wUwGek2)'
m = base64.b85decode(s85)
# print(m)
# 475532444B4E525549453244494E4A57475132544B514A54473432544F4E4A5547515A44474D4A5648415A54414E4257473434544B514A5647595A54514D5A5147553444474D5A5547453355434E5254475A42444B514A57494D3254534D5A5447555A444D4E5256494532444F4E4A57475A41544952425547343254454E534447595A544D524A5447415A55493D3D3D'
s16 = '475532444B4E525549453244494E4A57475132544B514A54473432544F4E4A5547515A44474D4A5648415A54414E4257473434544B514A5647595A54514D5A5147553444474D5A5547453355434E5254475A42444B514A57494D3254534D5A5447555A444D4E5256494532444F4E4A57475A41544952425547343254454E534447595A544D524A5447415A55493D3D3D'
k = base64.b16decode(s16)
# print(k)
s32 = 'GU2DKNRUIE2DINJWGQ2TKQJTG42TONJUGQZDGMJVHAZTANBWG44TKQJVGYZTQMZQGU4DGMZUGE3UCNRTGZBDKQJWIM2TSMZTGUZDMNRVIE2DONJWGZATIRBUG42TENSDGYZTMRJTGAZUI==='
w = base64.b32decode(s32)
# print(w)
s16 = '54564A4456455A3757544231583046795A5638305833417A636B5A6C593352665A47566A4D47526C636E303D'
x = base64.b16decode(s16)
#print(x)
s64 = 'TVJDVEZ7WTB1X0FyZV80X3AzckZlY3RfZGVjMGRlcn0='
flag = base64.b64decode(s64)
print(flag)
# b'MRCTF{Y0u_Are_4_p3rFect_dec0der}'
|
放一手出题人给的脚本和出题代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
#!/usr/bin/env python
#解题脚本
import base64
import re
def baseDec(text,type):
if type == 1:
return base64.b16decode(text)
elif type == 2:
return base64.b32decode(text)
elif type == 3:
return base64.b64decode(text)
elif type == 4:
return base64.b85decode(text)
else:
pass
def detect(text):
try:
if re.match("^[0-9A-F=]+$",text.decode()) is not None:
return 1
except:
pass
try:
if re.match("^[A-Z2-7=]+$",text.decode()) is not None:
return 2
except:
pass
try:
if re.match("^[A-Za-z0-9+/=]+$",text.decode()) is not None:
return 3
except:
pass
return 4
def autoDec(text):
while True:
if b"MRCTF{" in text:
print("\n"+text.decode())
break
code = detect(text)
text = baseDec(text,code)
with open("flag.txt",'rb') as f:
flag = f.read()
autoDec(flag)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
|
#!/usr/bin/env python
# 出题脚本
import base64
import re
key = "31214"
# key本来非常长。。似乎太难了改的简单了点
# key = "14332234124133132214311231"
flag = b"MRCTF{Y0u_Are_4_p3rFect_dec0der}"
def baseEnc(text,type):
if type == 1:
return base64.b16encode(text)
elif type == 2:
return base64.b32encode(text)
elif type == 3:
return base64.b64encode(text)
elif type == 4:
return base64.b85encode(text)
else:
pass
def baseDec(text,type):
if type == 1:
return base64.b16decode(text)
elif type == 2:
return base64.b32decode(text)
elif type == 3:
return base64.b64decode(text)
elif type == 4:
return base64.b85decode(text)
else:
pass
def finalEnc(text,key):
nf = text
count = 1
for i in key:
nf = baseEnc(nf,int(i,10))
#print("第"+str(count)+"次加密: ",nf)
count +=1
return nf
def finalDec(text,key):
nf = text
key = key[::-1]
print(key)
count = 1
for i in key:
nf = baseDec(nf,int(i,10))
#print("第"+str(count)+"次解密: ",nf)
count +=1
return nf
def detect(text):
try:
if re.match("^[0-9A-F=]+$",text.decode()) is not None:
return 1
except:
pass
try:
if re.match("^[A-Z2-7=]+$",text.decode()) is not None:
return 2
except:
pass
try:
if re.match("^[A-Za-z0-9+/=]+$",text.decode()) is not None:
return 3
except:
pass
return 4
def autoDec(text):
print("dec key:",end="")
while True:
if b"MRCTF{" in text:
print("\n"+text.decode())
break
code = detect(text)
text = baseDec(text,code)
print(str(code),end="")
fe = finalEnc(flag,key)
with open("flag.txt",'w') as f:
f.write(fe.decode())
'''
ff = finalDec(fe,key)
print(ff)
'''
ff = autoDec(fe)
|
voip:基于IP的语音传输---------------------------------from wiki
(英语:Voice over Internet Protocol,缩写:VoIP)是一种语音通话技术,经由网际协议(IP)来达成语音通话与多媒体会议,也就是经由互联网来进行通信。其他非正式的名称有IP电话(IP telephony)、互联网电话(Internet telephony)、宽带电话(broadband telephony)以及宽带电话服务(broadband phone service)。
VoIP可用于包括VoIP电话、智能手机、个人计算机在内的诸多互联网接入设备,通过蜂窝网络、Wi-Fi进行通话及发送短信[1]。
用 wireshark 打开问文件后,可以直接主菜单点击 电话——>VoIP电话 ——> 播放流 就可以听到声音
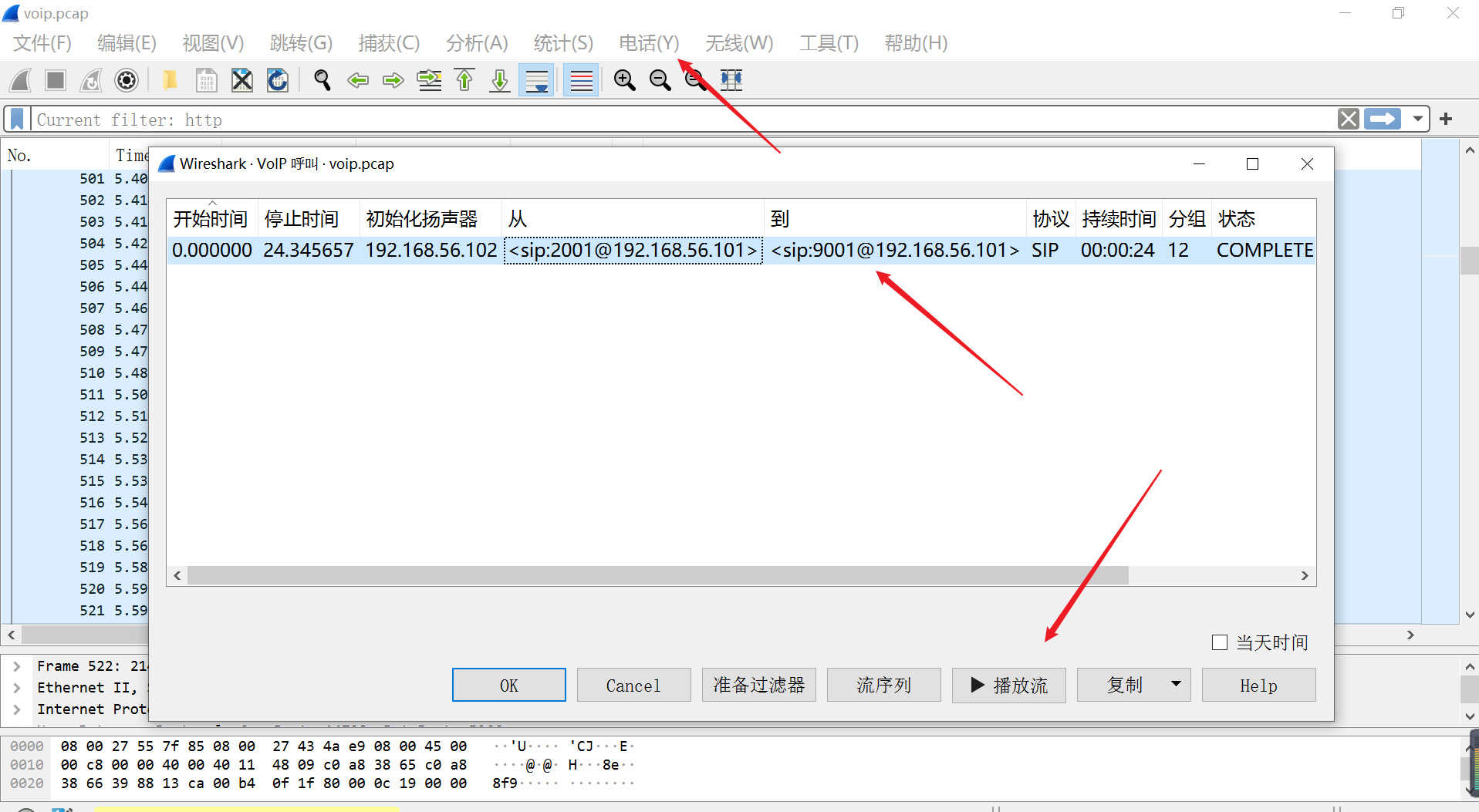
1
|
听到 flag 为:seccon{9001IVR}
|
用 Wireshark 可以知道,改文件使用的是RIP协议,工具栏中点击电话 ==> RIP ==> RIP流 ==>播放流 就可以听到声音
放一个大师傅的总结笔记:Ga1axy
BPG-------------------wiki
打开图片后,在 PNG 的末尾可以发现 有 BPG 的标志,将后面的内容提取出来打包为 .bpg文件
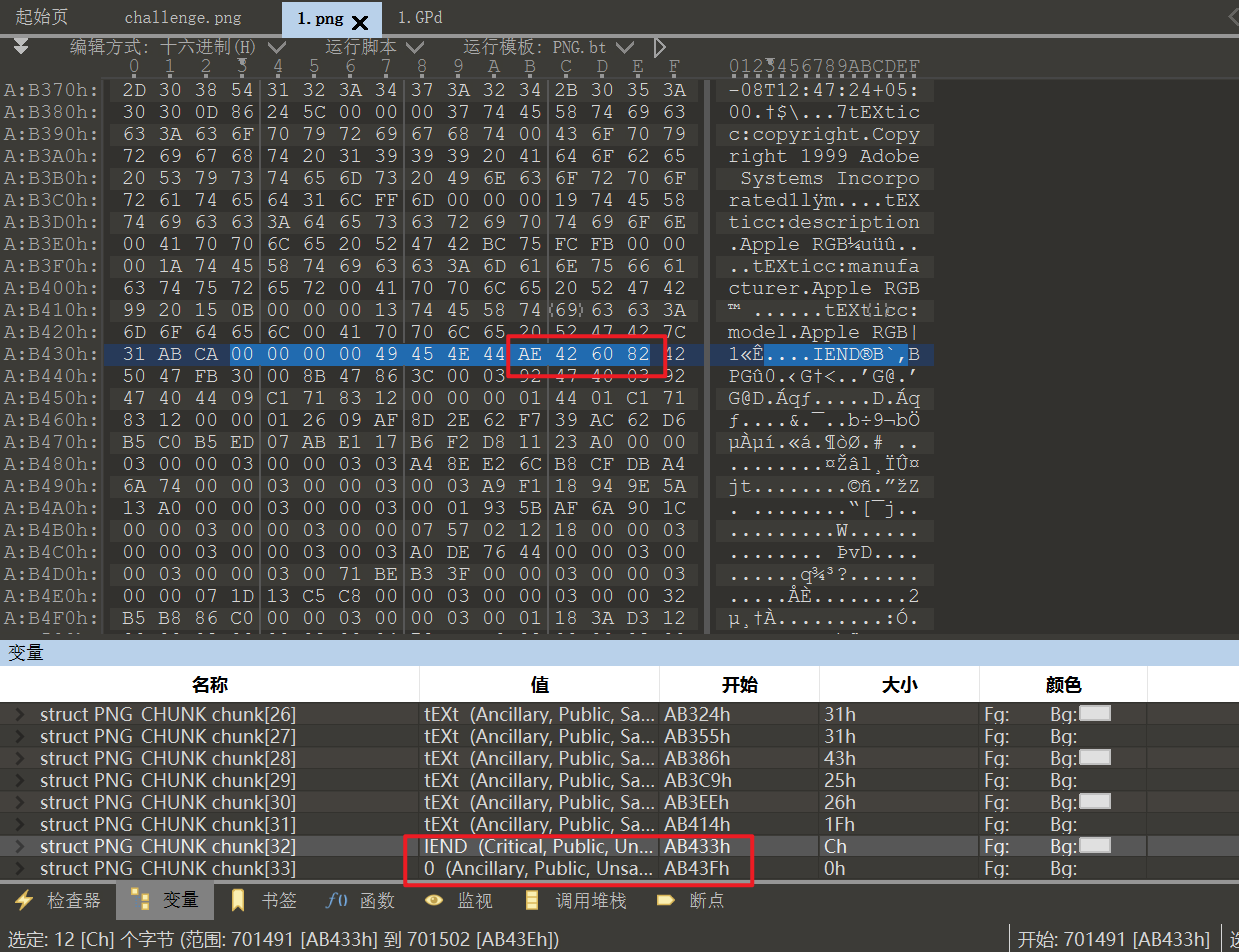
这里 bpg 文件用软件 Honeyview 可以正常打开
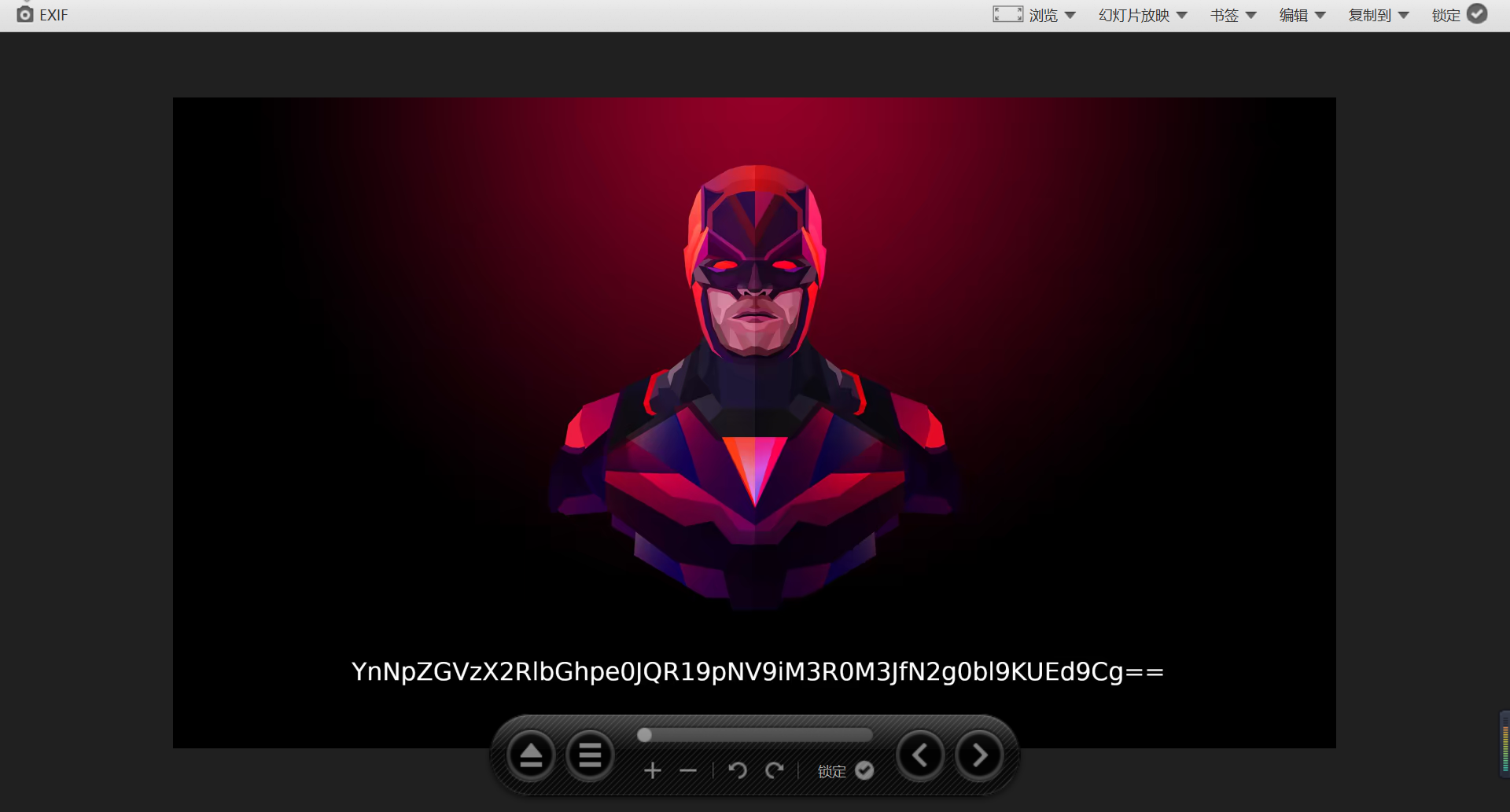
1
2
3
4
5
|
# YnNpZGVzX2RlbGhpe0JQR19pNV9iM3R0M3JfN2g0bl9KUEd9Cg=
base64解码
# bsides_delhi{BPG_i5_b3tt3r_7h4n_JPG}
|
stegosaurus(剑龙):用于在 Python 字节码中嵌入 Payload(有效载荷)的隐写术工具。
-
工具下载网站
-
用法:
Stegosaurus 是一种隐写术工具 ,允许在 Python 字节码(pyc 或 pyo)文件中嵌入任意有效负载。嵌入过程不会改变载体文件的运行时行为或文件大小,通常会导致低编码密度。有效载荷分散在整个字节码中,因此类似的工具 strings 不会显示实际的有效载荷。Python 的dis模块将在使用 Stegosaurus 嵌入有效载荷之前和之后返回相同的字节码结果。目前,对于这种类型的有效载荷传递,尚无已知的工作或检测方法。
剑龙需要 Python 3.6 或更高版本。
Stegosaurus 的基本用法如下:
$ python3 -m stegosaurus -h
usage: stegosaurus.py [-h] [-p PAYLOAD] [-r] [-s] [-v] [-x] carrier
positional arguments:
carrier Carrier py, pyc or pyo file
optional arguments:
-h, --help show this help message and exit
-p PAYLOAD, --payload PAYLOAD
Embed payload in carrier file
-r, --report Report max available payload size carrier supports
-s, --side-by-side Do not overwrite carrier file, install side by side
instead.
-v, --verbose Increase verbosity once per use
-x, --extract Extract payload from carrier file
1
2
3
|
# steghide提取jpg隐写文件
针对jpg格式图片的隐写
|
安装:
kali: apt-get install steghide
用法:
1
2
3
4
5
6
7
8
9
10
|
#隐藏文件
steghide embed -cf [图片或wav文件载体] -ef [待隐藏文件]
steghide embed -cf 1.jpg -ef 1.txt
#查看图片中嵌入的文件信息
steghide info 1.jpg
#提取图片中隐藏的文件
steghide extract -sf 1.jpg
|
将所有文件解压后得到:
hh.jpg , O_O , pwd.txt 这三个文件
非预期解:
1
2
3
|
用linux 命令 file 查看 O_O 文件,得到:
O_O: python 3.6 byte-compiled
google可以知道是 pyc文件
|
题目有提示过剑龙,说明题目进行了 stegosaurus 隐写
1
2
3
4
5
|
# kali调用stegosaurus -x 命令从载体中提取payload:
./stegosaurus -x O_O.pyc
==> flag{3teg0Sauru3_!1}
|
预期解:
1、查看 pwd.txt
1
2
|
# pwd.txt 打开后知道是颜文字加密,用在线网站解密得到:
welcom3!
|
2、 查看 hh.jpg 图片
1
2
|
# 在图片的属性中提示有密钥
@#$%^&%%$)
|
3、用 steghide 提取 jpg 图片中隐写的文件
1
|
steghide extract -sf hh.jpg
|
得到 secret.txt 文件:
想要flag吗?解出我的密文吧~
U2FsdGVkX1/7KeHVl5984OsGUVSanPfPednHpK9lKvp0kdrxO4Tj/Q==
经过尝试,是 DES加密,这里找一个好点的 解密网站
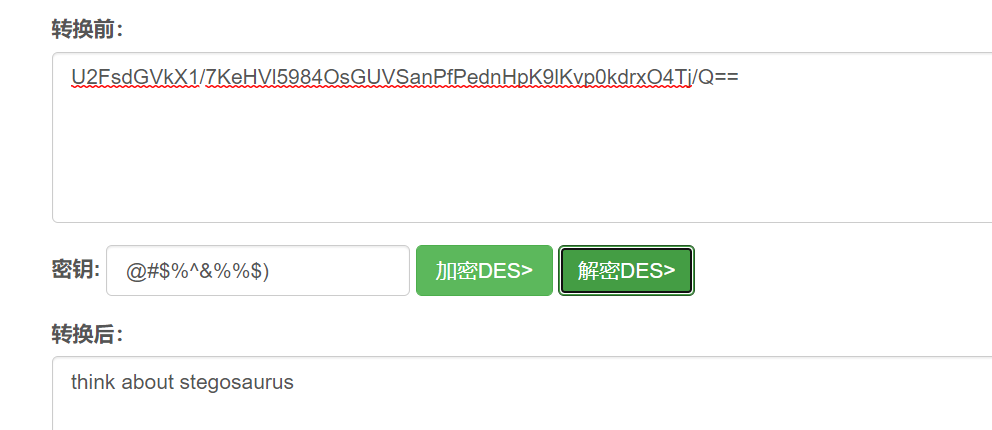
剩下的操作就是用 stegosaurus 隐写
就普通的在jpg中隐写了zip文件,用binwalk 分离 或者手动分离
用 010 editor 打开,在jpg文件尾可以看到明显的 zip 文件头 50 4B 03 04,然后手动分离出 zip文件
解压缩拿到 flag{7h475_4c7u4lly_r34lly_cu73_7h0u6h}
在Linux中,可执行文件的格式是ELF格式。
1、file 命令查看文件的类型
2、./ 命令在当前目录下直接执行程序
3、strings命令在对象文件或二进制文件中查找可打印的字符串。
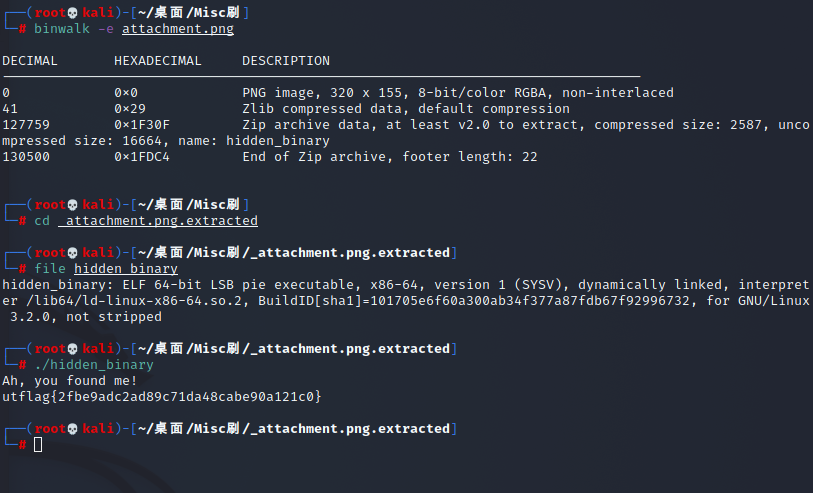
将图片用binwalk -e 命令提取隐藏文件,发现有 hidden_binary 文件,
用 file hidden_binary 命令查看文件类型,可知为 ELF 文件,直接 ./hidden_binary 运行拿到
flag{2fbe9adc2ad89c71da48cabe90a121c0}
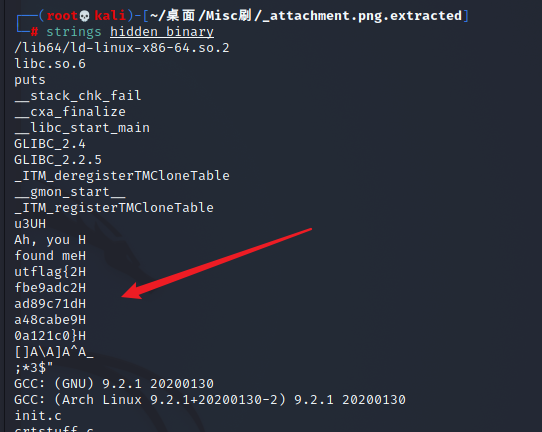
还可以使用 strings 命令,来查看文件中的所有ASCLL可打印字符
Unicode编码有以下四种编码方式:
源文本: The
&#x [Hex]: The
&# [Decimal]: The
\U [Hex]: \U0054\U0068\U0065
\U+ [Hex]: \U+0054\U+0068\U+0065
unicode在线解码
站长工具
Steghide文件隐写:
用法:
1
2
3
4
5
6
7
8
9
10
|
#隐藏文件
steghide embed -cf [图片或wav文件载体] -ef [待隐藏文件]
steghide embed -cf 1.jpg -ef 1.txt
#查看图片中嵌入的文件信息
steghide info 1.jpg
#提取图片中隐藏的文件
steghide extract -sf 1.jpg
|
打开 out.wav 音频文件,从音频分析未果。用 steghide 命令查看是否有隐写的文件
用steghide extract -sf out.wav 命令分离出 download.txt 文件
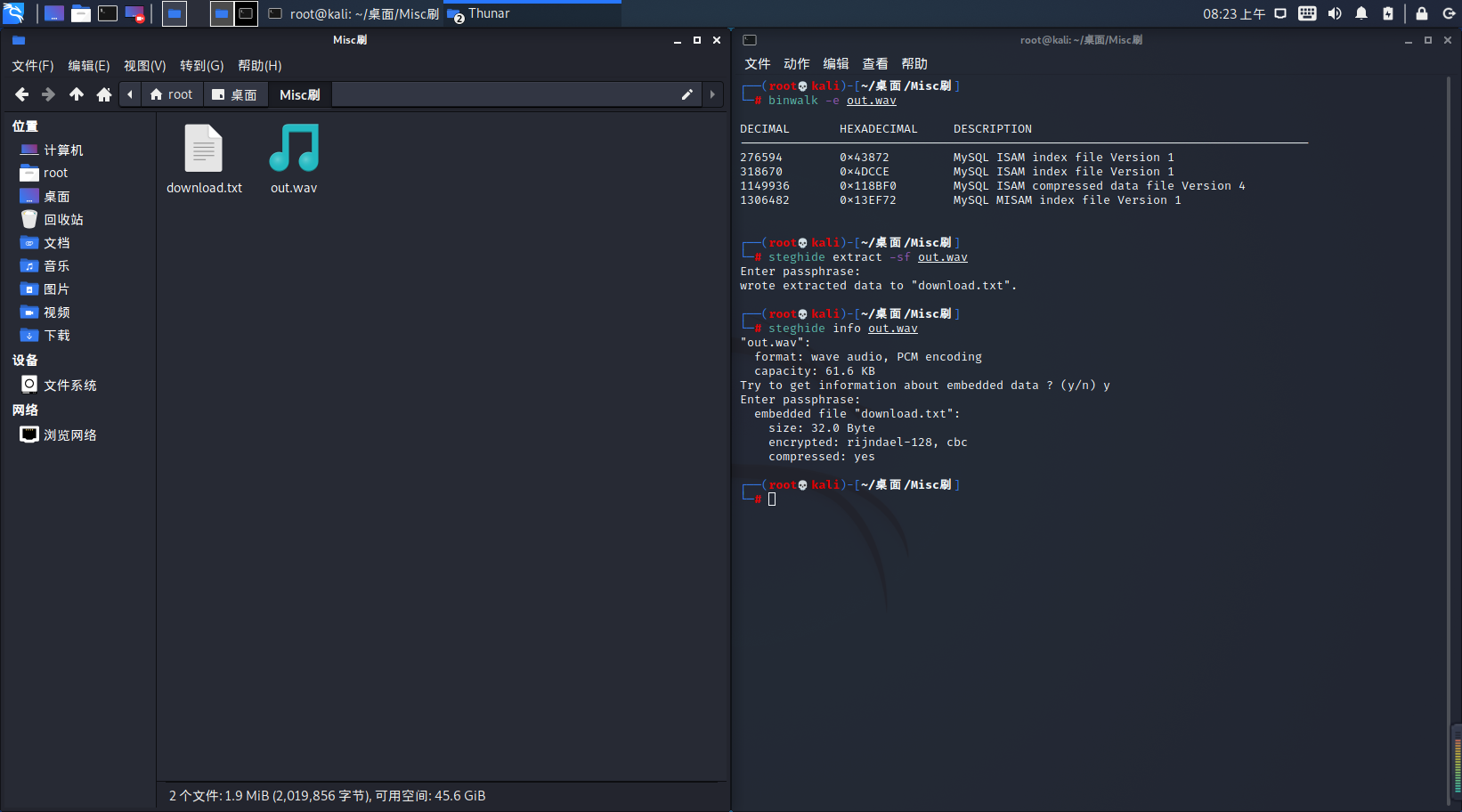
下载图片后,打不开。用010editor查看图片信息,发现文件头错误 应该为 89 50 4E 47。
打开后得到下面:
1
|
\u0034\u0030\u0037\u0030\u000d\u000a\u0031\u0032\u0033\u0034\u000d\u000a
|
用在线工具解码unicode在线解码
得到:flag{5304}
相比传统水印添加的方法,频域盲水印的隐匿性与鲁棒性(抗攻击性)都更高,能抵挡大部分常见的攻击。
学习文章:
频域盲水印攻击性测试
盲水印和图片隐写术
Misc常用工具
Blind WaterMark盲水印:
得到两张图片 huyao.png 、stillhuyao.png,看别人写的题解说是频域盲水印,没接触过...
直接用下面的python脚本跑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
import cv2
import numpy as np
import random
import os
from argparse import ArgumentParser
ALPHA = 5
def build_parser():
parser = ArgumentParser()
parser.add_argument('--original', dest='ori', required=True)
parser.add_argument('--image', dest='img', required=True)
parser.add_argument('--result', dest='res', required=True)
parser.add_argument('--alpha', dest='alpha', default=ALPHA)
return parser
def main():
parser = build_parser()
options = parser.parse_args()
ori = options.ori
img = options.img
res = options.res
alpha = options.alpha
if not os.path.isfile(ori):
parser.error("original image %s does not exist." % ori)
if not os.path.isfile(img):
parser.error("image %s does not exist." % img)
decode(ori, img, res, alpha)
def decode(ori_path, img_path, res_path, alpha):
ori = cv2.imread(ori_path)
img = cv2.imread(img_path)
ori_f = np.fft.fft2(ori)
img_f = np.fft.fft2(img)
height, width = ori.shape[0], ori.shape[1]
watermark = (ori_f - img_f) / alpha
watermark = np.real(watermark)
res = np.zeros(watermark.shape)
random.seed(height + width)
x = range(height / 2)
y = range(width)
random.shuffle(x)
random.shuffle(y)
for i in range(height / 2):
for j in range(width):
res[x[i]][y[j]] = watermark[i][j]
cv2.imwrite(res_path, res, [int(cv2.IMWRITE_JPEG_QUALITY), 100])
if __name__ == '__main__':
main()
|
使用方法:
1
|
python2 blidwatermark.py --original huyao.png --image stillhuyao.png --result out.png
|

得到:flag{BWM_1s_c00l}
注意: 上面的脚本中缺失 cv2 库的话,使用下列命令安装
1
|
pip2 install opencv-python==4.2.0.32
|
原因: Opencv 最新版不再支持 Python 2.7,而 pip install opencv-python 命令会下载最新版本Opencv。
因此需要安装时指定opencv的老版本,最后一个支持 Python 2.7 的 Opencv 版本是 4.2.0.32。

